Semantic Group Inferenz: Den Suchraum einengen
Nachdem der Intent bekannt ist, wird der Vektorraum thematisch verengt. Das übernimmt der SemanticGroupInferer.
Die sechs Gruppen
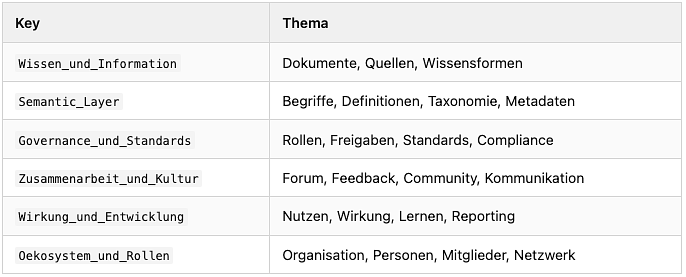
Jede Section im Kompendium trägt beim Embedding ihre Gruppe als Präfix:
"SG: Wirkung_und_Entwicklung\n\n<Textinhalt>".
Das ist der entscheidende Punkt: Die Vektoren im Index sind mit SG-Kontext eingebettet.
Damit der Retrieval funktioniert, muss auch die Anfrage-Query mit demselben Kontext eingebettet werden — sonst vergleicht man symmetrisch unterschiedliche Repräsentationen.
Scoring: Wörter, Phrasen, Intent-Bias

Phrasen wie "welchen nutzen" zählen 2,5× so viel wie Einzelwörter. Eine why-Frage bekommt automatisch einen starken Bias auf Wirkung_und_Entwicklung — auch wenn die Frage kein einziges Keyword dieser Gruppe enthält.
Symmetrisches Embedding
Die Top-2-Gruppen nach Score ergeben den Kontext-String, der der Frage vorangestellt wird:
Dieser angereicherte String wird eingebettet — nicht die rohe Frage. Das Ergebnis ist ein Abfragevektor, der im selben Teilraum liegt wie die Sections, die beim Indexaufbau mit demselben Präfix eingebettet wurden.
Intent und SG im Zusammenspiel
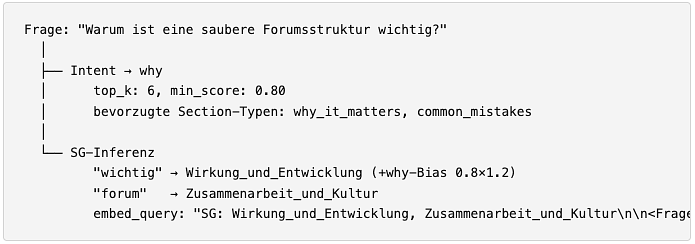
Intent steuert wie gesucht wird. Semantic Group steuert wo gesucht wird.
Der Fragenkatalog als Teststrecke
Jede der ~40 Shortcut-Regeln hat eine Geschichte: eine Frage, die falsch klassifiziert wurde, ein Retrieval, das dadurch in die falsche Richtung suchte, und ein Testlauf, der den Fehler sichtbar machte. Der Fragenkatalog — generiert direkt aus dem Kompendium, eine Frage pro Section — war dabei das wichtigste Instrument. Die WARN-Zeilen in den Testläufen haben nicht nur den Classifier verbessert, sondern Lücken im Kompendium selbst sichtbar gemacht: Sections, die thematisch isoliert lagen oder zu wenig Kontext enthielten.
Fazit
Intent-Klassifikation für deutsche Wissensfragen ist kein Leistungsproblem — ein lokales llama3 ist groß genug, um die Aufgabe grundsätzlich zu verstehen. Es ist ein Präzisionsproblem, das aus der Mehrdeutigkeit der deutschen Fragesprache entsteht. Die Shortcut-Layer-Regeln kodieren dieses Kontextwissen deterministisch. Das LLM übernimmt den Rest. Die Semantic Group Inferenz ergänzt diesen Ansatz auf der Inhaltsebene: Sie sorgt dafür, dass der Abfragevektor im selben thematischen Teilraum landet wie die Sections, die eine Antwort enthalten könnten.