x Treffer ab Ähnlichkeitswert y ?
Das liefert mittelmäßige Ergebnisse für alle statt gute für jeden.
Die intent-Klassifikation steuert drei Dinge gleichzeitig:
- die Retrieval-Parameter,
- welche Section-Typen bevorzugt werden, und
- welche Semantic Groups beim Embedding priorisiert werden.
Die Klassifikationslogik baut dabei auf zwei Konzepten auf, die durch die gesamte RAG-Pipeline laufen.
top_k ist die maximale Anzahl an Textabschnitten (Sections), die der Retrieval-Schritt als Kontext an das Sprachmodell übergibt. Ein höheres top_k liefert mehr Kontext — aber auch mehr Rauschen. Ein niedrigeres top_k ist präziser, riskiert aber, relevante Passagen zu übersehen.
min_score ist der Ähnlichkeits-Schwellenwert. Intern arbeitet die Datenbank mit Cosinus-Distanz: Zwei identische Vektoren haben Distanz 0, völlig verschiedene Vektoren Distanz 1. min_score entspricht dem erlaubten Höchstwert dieser Distanz — ein Abschnitt, der weiter entfernt ist als min_score, wird nicht in den Kontext aufgenommen, auch wenn top_k noch nicht erreicht ist. Je niedriger der Wert, desto strenger der Filter.
Beide Parameter werden pro Intent gesetzt:


Das „Wie"-Problem
Im Englischen ist „How do I..." ein starkes Signal für eine Handlungsanweisung. Im Deutschen ist „Wie" radikal mehrdeutig:
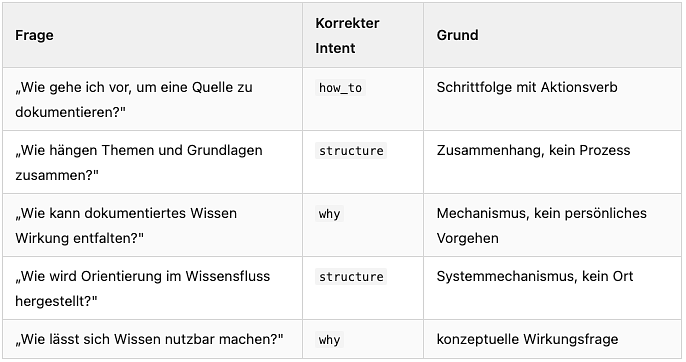
Unser LLM klassifizierte anfangs viele dieser Fragen als how_to.
Das englische Training-Prior — „Wie" → Prozess — war zu stark.
Die Lösung: eine Heuristik, die prüft, ob ein persönliches Handlungssubjekt (ich, man, wir) oder ein konkretes Aktionsverb vorhanden ist:

„Was ist" ist keine Definition
Das Muster Was ist X? löst intuitiv definition aus. Deutsche Wissensfragen bauen dasselbe syntaktische Gerüst für semantisch völlig andere Intents:

Die Lösung: Spezifische Shortcuts greifen vor dem allgemeinen definition-Shortcut:

Die Navigations-Falle und das Umlaut-Problem
navigation ist für räumliche Orientierung gedacht: „Wo finde ich X?". Das LLM erweiterte den Scope auf konzeptuelle Orientierung: „Wie wird Orientierung im Wissensfluss hergestellt?" landete als navigation. Der Fix: ein Shortcut fängt das Muster wie wird X hergestellt/erzeugt/erreicht ab und klassifiziert es als structure — noch bevor die Navigation-Regeln greifen.
Deutsch verwendet Umlaute — und diese verhalten sich in Regex-Matching unprediktabel je nach Encoding und Unicode-Normalisierung. Dazu kommt das geschützte Leerzeichen ( ) aus kopierten Kompendium-Texten.
Jede Matching-Operation läuft deshalb über:

Die dreistufige Klassifikations-Architektur

temperature: 0.0 und fester seed sorgen für Reproduzierbarkeit — Klassifikation ist eine Entscheidungsaufgabe, keine kreative.
num_predict: 6 begrenzt die Ausgabe auf das Label.